 Les codes de la Bible exactement
Les codes de la Bible exactement
Le professeur Rips et son équipe poursuivirent les recherches avec toute la rigueur scientifique nécessaire.
L'essentiel des recherches porta sur le livre de la Genèse, et en particulier sur les deux premiers chapitres, dans lesquels un nombre impressionnant de mots codés furent mis à jour.
Le protocole d'expérimentation fut ainsi établi au départ:
1. On suppose que l'hypothèse est valide. On détermine certains endroits de la Torah susceptibles de renfermer des mots codés.
2. On sélectionne des mots à rechercher, particulièrement significatifs en fonction du contexte, de l'histoire, de leur importance symbolique ou de la tradition orale.
3. On procède à une analyse statistique des mots sélectionnés, puis on fait des vérifications additionnelles.
Les arbres du jardin
Une des expérimentations "a priori" de Rips porta sur les plantes et les arbres de la création, dans le passage compris entre le premier et le dernier verset qui les mentionnent:
Et Dieu dit: Voici, je vous donne toute herbe portant de la semence et qui est à la surface de toute la terre, et tout arbre ayant en lui du fruit d'arbre et portant de la semence: ce sera votre nourriture.
Genèse 1:29
L'Éternel Dieu fit pousser du sol des arbres de toute espèce, agréables à voir et bons à manger, et l'arbre de la vie au milieu du jardin, et l'arbre de la connaissance du bien et du mal.
Genèse 2:9
L'Éternel Dieu donna cet ordre à l'homme: Tu pourras manger de tous les arbres du jardin;
mais tu ne mangeras pas de l'arbre de la connaissance du bien et du mal, car le jour où tu en mangeras, tu mourras.
Genèse 2:16-17
Dans ces
passages aucun nom de plante ou d'arbre n'est mentionné.
Rips prédit qu'à l'intérieur de ces passages on devrait trouver les noms de tous les arbres et plantes de la terre d'Israel désignés dans la tradition juive, soit vingt-cinq au total.
Après avoir rentré les vingt-cinq noms dans le programme de recherche, tous sont apparus en code, à savoir:
Le blé, la vigne, le raisin, le marronnier, la myrte, le palmier dattier, l'acacia, le lyciet, le cèdre, le pistachier, le figuier, le saule, le grenadier, l'aloe, le tamaris, le chêne, le peuplier, le cassier, l'amandier, le térébinthe, l'aubépine, le noisetier, le citronnier, le cyprès.
Bien sûr, comme nous l'avions vu dans les exemples précédents, il est normal que des mots de trois ou quatre lettres apparaissent partout de façon aléatoire; ce qui est exceptionnel ici c'est que la plupart des intervalles entre les lettres (excepté "marronnier" et "peuplier") sont très courts, de façon à être compris dans cette portion de texte (ce sera une constante dans la découverte des codes de la Torah), ensuite, il n'y a aucun autre passage de cette longueur dans toute la Genèse qui contienne autant d'arbres à des intervalles inférieurs à 20.
Il calculèrent les probabilités de trouver ici les 25 espèces, elles sont de l'ordre de 1/100 000.
Les amalgames
Un autre phénomène qui fut découvert dans la Genèse est la tendance qu'a un mot clé à apparaitre plusieurs fois en code à un endroit identifié: c'est le phénomène d'amalgame ("clusters" en Anglais), les occurrences du mot codé étant anormalement proches les unes des autres.
C'est le cas par exemple des mots:
"Eden",
"rivière",
"lieu",
"amas" (des eaux)
Le mot hébreu
makom (lieu, endroit) possède une nuance qui n'est pas rendue en français, avec un sens d' "endroit spécial" ou "lieu saint".
Dieu dit: Que les eaux qui
sont au-dessous du ciel se rassemblent en un seul lieu, et que le sec paraisse.

Autour du mot-clé מקום(makom) "lieu" dans le texte, les mêmes mots "lieu" en codes de petits intervalles de lettres (principe du code minimal), gravitent à une proximité statistiquement significative.
Nous n'avons présenté ici que quelques exemples parmi un nombre considérable d'amalgames qui furent découverts par Rips et son équipe.
Ils émirent l'hypothèse qu'il pouvait s'agir d'un effet mécanique de la langue hébraïque, mais des tests additionnels confirmèrent qu'il n'en était rien, ils étaient en présence d'un phénomène vraiment intentionnel.
Cependant, la controverse inévitable qui ne manquera pas de se présenter ici sera de prétendre que l'on a très bien pu retenir les mots statistiquement signifiant et écarter les autres.
Conscients de cette possibilité, Rips et Michaelson poussèrent l'analyse à son étape suivante: Ils examinèrent tous les mots de cette section de la Genèse, recherchant systématiquement les effets d'amalgame. En voici les résultats:
- 40% des mots produisent un fort effet d'amalgame
- 40% produisent un effet d'amalgame modéré
- 20% ne produisent pas d'amalgames
De tels résultats dépassent de très loin ce que l'on s'attendrait à trouver par hasard dans un texte quelconque.
Théorie des codes de la torah
C'est ainsi que le professeur Rips et ses collaborateurs identifièrent une série de principes relatifs à ces codes, énumérés comme suit:
- La Torah doit être considérée comme un texte écrit en deux dimensions: Un texte clair, dont nous connaissons l'importance, et un texte crypté, par séquences de lettres équidistantes (ELS), entrant en résonance avec le texte en clair.
- Le texte crypté a une tendance statistique à faire apparaitre des mots-clé à des endroits déterminés, à une plus grande fréquence que des mots apparaissant au hasard.
- Les mots-clé ont tendance à apparaitre plusieurs fois à proximité les uns des autres.
- Les mots-clé sont soit des mots uniques qui apparaissent plus d'une fois ("lieu", "amas", "lumière", "eaux", "mers"...), ou des mots fortement corrélés entre eux qui apparaissent à proximité l'un de l'autre (Boaz-Ruth, Ishaï-David, homme-femme...)
- Le degré de proximité des mots-clé est statistiquement supérieur à celui que l'on trouve pour ces mêmes mots dans des textes de contrôle (monkey texts).
- Le principe du code minimal: En l'absence d'autres éléments déterminant (par exemple les codes à valeur symbolique tels que 7, 13, 22, 50... ou leur multiples), les codes les plus signifiants sont ceux qui ont l'intervalle de lettres le plus petit sur la totalité ou la majeure partie du texte. Par exemple, si dans tout le texte de la Genèse, un mot apparait par des ELS de 4, 9, 29, 81, 187 lettres, c'est la plus petite ELS soit celle de 4 lettres qui est déterminante. Ce principe reflète une certaine logique: lorsqu'un ensemble de mots ayant une forte corrélation apparaissent en code très proches les uns des autres, plus les intervalles entre leurs lettres sont petits, plus l'espace de texte qu'ils occupent est étroit. La probabilité d'un acte intentionnel, pointant un élément très précis du texte devient alors très élevée.
-
Ces codes sont spécifiques à la Torah, on ne les trouve dans aucuns autres textes, qu'ils soient profanes ou religieux.Notons ici
toutefois que d'autres chercheurs ont découverts des codes dans quelques autres livres du Tanakh (Esaïe, Ézékiel, et quelques psaumes), mais pas de façon systématique comme dans la
Torah, et ces découvertes n'ont pour l'instant pas été validées par l'équipe scientifique du Professeur Rips; nous y reviendrons par la suite.
Pour une meilleure compréhension, schématisons le phénomène d'amalgames dans les tableaux ci-dessous:
Le point rouge représente le mot-clé dans le texte en clair.
Les points noirs représentent le même mot-clé qui apparait par séquences de lettres équidistantes dans le texte crypté.
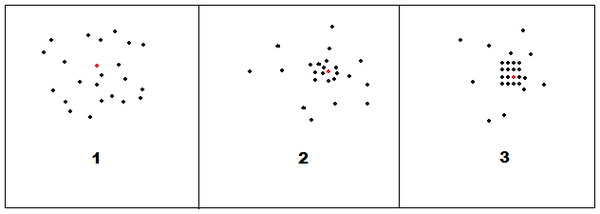
- Dans le premier tableau, les points noirs sont répartis de façon aléatoire, il n'y a pas d'amalgame. Leur répartition ne laisse pas présumer un acte intentionnel quelconque.
-
Dans le deuxième tableau, on observe clairement l'amalgame, un maximum d'ELS s'agglutinent et se trouvent à proximité du mot-clé dans le texte en clair, de la
même façon que l'on observerait le score d'un tireur ayant pointé une cible.
- Le troisième tableau est encore plus remarquable: Non seulement nous sommes en présence d'un amalgame, mais celui-ci est parfaitement ordonné et forme une figure géométrique significative. Nous allons tout de suite en voir quelques exemples.
